This project, the code, and diagrams can be found at https://github.com/aryanka15/FPGA_Image_Processor (this article describes the project up to commit 9506cca)
If you haven't already, go and read Part 1 on my blog to get an intro to this project. If you have, here's a quick recap.
Recap
Previously, the accelerator could process an entire 512x512 BMP in 20ms. Not very fast at all. A C program can hit 1 ms when optimized, so there's definitely room for improvement. While the MAC is pipelined, the controller is not taking advantage of the pipelining yet. Also, each of the three line buffers need to be loaded for every line processed, even the data we are reusing between convolutions! This is a huge inefficiency which needs to be addressed in the next iteration.
MAC Pipeline
For reference, here are the current MAC and controller:
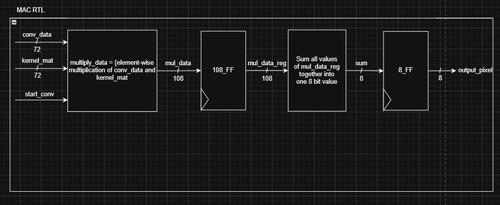
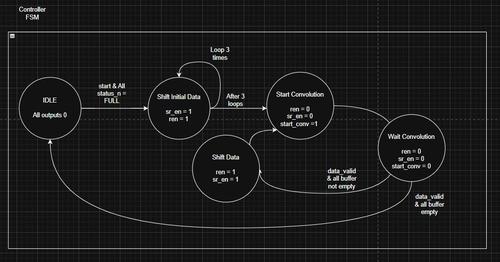
We are waiting for each pixel to be processed before inputting the previous pixel. But each pixel still takes 3 clock cycles, so this is a huge inefficiency. In order to fix this, we need to constantly shift data and read data from the buffers, in order to get a clock output every cycle. This is a simple change, resulting in this FSM:
After the Shift Init state, which shifts the first 3x3 window using a counter (loop 3 times), the FSM keeps shifting and reading from the buffer until all the buffers are empty. The Last Data and Wait Convolution states are present to ensure any leftover pixels in the pipeline are properly processed.
Essentially, after the initial 3 cycle latency, the MAC outputs a pixel every cycle due to the pipelining. In simulation, this brought a 4x improvement
For those unfamiliar with pipelining, here's a visualization:
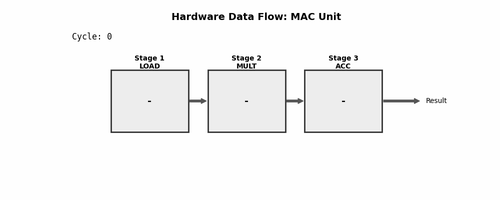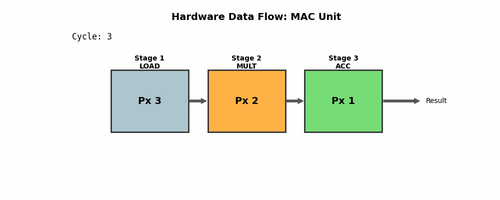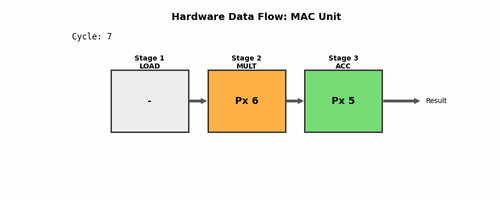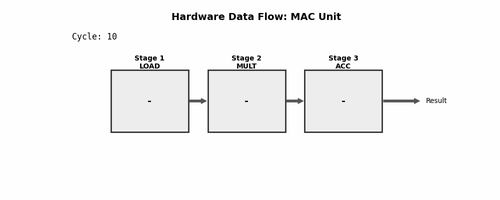
Fun Fact: I made this using Gemini. It gave me a Python script to generate this, which is pretty cool.
So.. now the whole convolution can run in 5 ms, which is pretty good. But there's still one big inefficiency to fix. We're waiting for the line buffers to re-fill before every line that is processed. Add to that, we're refilling ALL THREE line buffers, even though two are reused for every consecutive convolution. We should be able to reuse line buffers, but also fill the next line of pixels while performing the current convolution.
Rotating Buffer
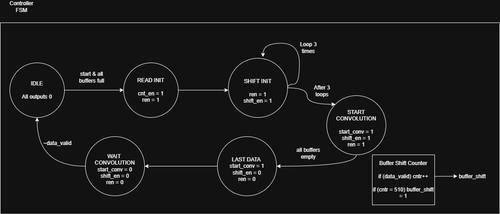
The solution is simple: add another line buffer. Something we can fill while the convolution is happening. But the logic becomes more complicated, we have to be able to switch the active line buffers used in the convolution, and the line buffer that is being written to. Additionally, the current FIFO blocks reading a line buffer once it has been fully read once, so we need to reset the read pointer in each re-used line buffer.
Here are the new RTL diagrams:
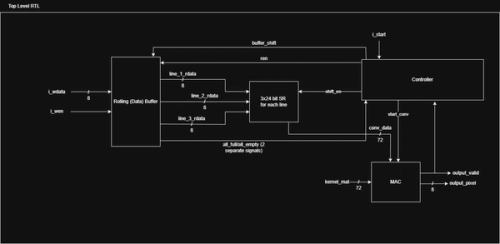
The top-level RTL removes the three line buffers for a single Rolling Data Buffer module. Additionally, there is only one serial data input instead of three separate inputs, because we want to be able to stream data, from something like a camera HDMI port or I2C/SPI peripheral. True data streaming requires much more processing but this is a decent start.
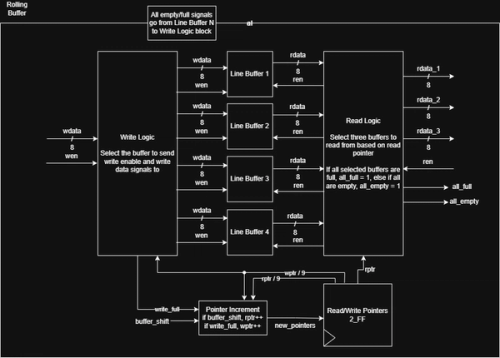
The rolling buffer contains four line buffers. The read/write pointers in the context of a rolling buffer point to which buffers are being used for reading/writing. For example, and rptr of 0 means Line Buffers 1, 2, and 3 are read from, and a wptr of 3 means Line Buffer 4 is being written to. The read and write logic act as muxes that switch between the buffers based on the pointers.
There is a lot more logic in this buffer, and you can see that in the SystemVerilog code on GitHub.
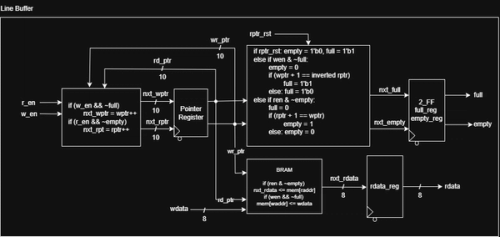
The updated line buffer is mostly the same, except for new rptr_rst logic that allows the rptr to be reset, so that we can re-read the current data in the line buffer.
This new architecture allows the user/SoC to stream data almost continuously and also perform convolutions.
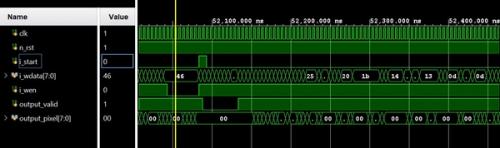
Here, you can see that the start signal goes high and the wen signal is also high. Several cycles later, the output_valid signal goes high, providing one output per cycle while the SoC is streaming data on the wdata line. This is the power of efficient architecture.
Going Even Faster
This runs the full convolution of an image in a little over 1ms. But there are a few issues, even with this design.
- The SoC can't truly stream data continuously. Streaming is slightly faster than the convolution, so if it continues streaming after the line buffer is full, it will drop those pixels. There needs to be some signal to tell the SoC or user to start/stop streaming
- We're currently only as fast as software on a high-clock CPU. This FPGA is running at 200 MHz vs a >4 GHz commercial CPU. The difference can be made with parallelization. GPUs, TPUs, and other accelerators are better than a CPU because they run efficient computation for specific tasks in batches. This is what our current design is missing.
On the surface, this means instantiating more MACs and consuming a little more power. However, we also have to increase the bandwidth of our design. If we did 4 pixels (32 bits), for example, we would also need to be able to load 4 pixels into the line buffer per cycle so that we're not waiting on data to be streamed, which would defeat the purpose of parallelization. Luckily, a 32-bit CPU can generally process data in 32 bit chunks, so this is perfect. For a 64-bit CPU, this can be done in 64-bit chunks.
I'm yet to start work on these improvements, so stay tuned for Part 3!!!